
문서 단어 행렬(DTM)의 표기법
문서 단어 행렬(DTM)이란 다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것을 말한다. 쉽게 생각하면 각 문서에 대한 BoW를 하나의 행렬로 만든 것으로 생각할 수 있으며, BoW와 다른 표현 방법이 아니라 BoW 표현읋 다수의 문서에 대해서 행렬로 표현하고 부르는 용어이다. 예를 들어 이렇게 4개의 문서가 있다고 하자.
문서1 : 먹고 싶은 사과
문서2 : 먹고 싶은 바나나
문서3 : 길고 노란 바나나 바나나
문서4 : 저는 과일이 좋아요
띄어쓰기 단위 토큰화를 수행한다고 가정하고, 문서 단어 행렬로 표현하면 다음과 같다.
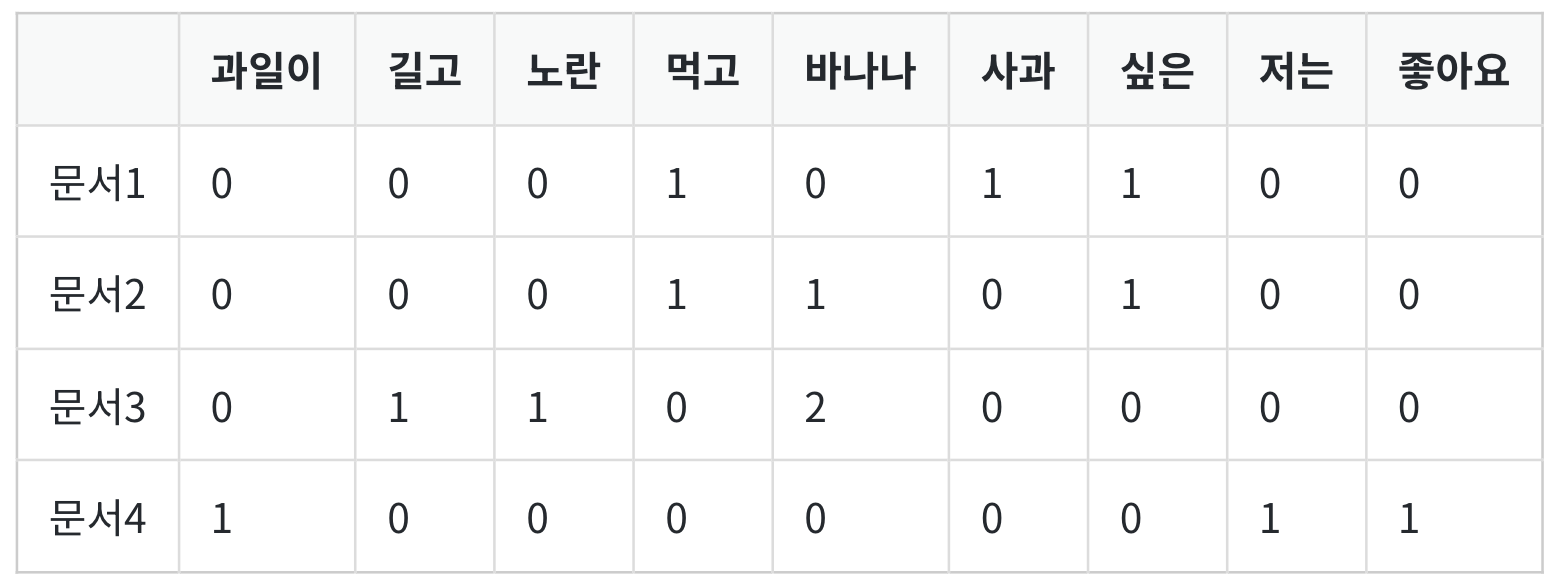
각 문서에서 등장한 단어의 빈도를 행렬의 값으로 표기한다. 문서 단어 행렬은 문서들을 서로 비교할 수 있도록 수치화할 수 있다는 점에서 의의를 갖는다. 만약 필요에 따라서는 형태소 분석기로 단어 토큰화를 수행하고, 불용어에 해당되는 조사들 또한 제거하여 더 정제된 DTM을 만들 수도 있을 것이다.
문서 단어 행렬의 한계
1) 희소 표현
원-핫 벡터는 단어 집합의 크기가 벡터의 차원이 되고 대부분의 값이 0이 되는 벡터이다. 원-핫 벡터는 공간적 낭비와 계산 리소스를 증가시킬 수 있다는 점에서 단점을 가진다. DTM도 마찬가지다. DTM에서의 각 행을 문서 벡터라고 해 보자.각 문서 벡터의 차원은 원-핫 벡터와 마찬가지로 전체 단어 집합의 크기를 가진다. 만약 가지고 있는 전체 코퍼스가 방대한 데이터라면 문서 벡터의 차원은 수만 이상의 차원을 가질 수도 있다. 또한 많은 문서 벡터가 대부분의 값이 0을 가질 수도 있다. 당장 위에서 예로 들었던 문서 단어 행렬의 모든 행이 0이 아닌 값보다 0의 값이 더 많은 것을 볼 수 있다.
원-핫 벡터나 DTM과 같은 대부분의 값이 0인 표현을 희소 벡터 또는 희소 행렬이라고 부르는데, 희소 벡터는 많은 양의 저장 공간과 높은 계산 복잡도를 요구한다. 이러한 이유로 전처리를 통해 단어 집합의 크기를 줄이는 일은 BoW 표현을 사용하는 모델에서 중요할 수 있다. 앞서 배운 텍스트 전처리 방법을 사용해 구두점, 빈도 수가 낮은 단어, 불용어를 제거하고, 어간이나 표제어 추출을 통해 단어를 정규화하여 단어 집합의 크기를 줄일 수 있다.
2) 단순 빈도 수 기반 접근
여러 문서에 등장하는 모든 단어에 대해서 빈도 표기를 하는 이런 방법은 때로는 한계를 가지기도 한다. 예를 들어 영어에 대해서 DTM을 만들었을 때, 불용어인 the는 어떤 문서이든 자주 등장할 수 밖에 없다. 그런데 유사한 문서인지 비교하고 싶은 문서1, 문서2, 문서3에서 동일하게 the가 빈도수가 높다고 해서 이 문서들이 유사한 문서라고 판단해서는 안 된다.
각 문서에서 중요한 단어와 불필요한 단어들이 혼재되어 있다. 앞서 불용어와 같은 단어들은 빈도수가 높더라도 자연어 처리에 있어 의미를 갖지 못하는 단어라고 언급한 바 있다. 그렇다면 DTM에 불용어와 중요한 단어에 대해서 가중치를 줄 수 있는 방법은 없을까? 이러한 아이디어를 적용한 TF-IDF가 있다.
'NLP > 딥러닝을 이용한 자연어 처리 입문' 카테고리의 다른 글
| [NLP] 4-1. 코사인 유사도(Cosine Similarity) (0) | 2024.01.02 |
|---|---|
| [NLP] 3-4. TF-IDF(Term Frequency-Inverse Document Frequency) (1) | 2023.12.26 |
| [NLP] 3-2. Bag of Words(BoW) (0) | 2023.12.21 |
| [NLP] 3-1. 다양한 단어의 표현 방법 (0) | 2023.12.21 |
| [NLP] 3. 카운트 기반의 단어 표현 (0) | 2023.12.21 |