이전 글인 Word2Vec 논문 리뷰에 이어 구현을 진행한다.
해당 논문에서 소개된 CBOW를 구현한다.
전반적인 구현 과정
- 더미 데이터를 생성한다.
- 해당 데이터를 띄어쓰기를 기준으로 쪼개 단어로 이루어진 시퀀스 리스트를 생성한다.
- 해당 시퀀스에 있는 단어들을 중복을 제거해 단어 : 인덱스 값을 가지는 딕셔너리를 생성한다.
- 시퀀스 리스트와 딕셔너리를 활용해 CBOW 모델 학습을 위한 데이터셋을 생성한다.
- 모델 학습을 위한 DataLoader를 생성한다.
- CBOW 모델을 정의한다.
- CBOW 모델과 loss, optimizer를 선언하고 학습을 진행한다.
- 단어 간의 유사도를 확인한다.
0. 라이브러리 설정
해당 과정에서 사용할 패키지들을 불러온다.
import torch
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
import torch.optim as optim
from torch.nn import functional as F
from torch import nn
1. 데이터 준비
간단히 논문의 모델의 성능을 확인하기 위해 더미 데이터를 사용한다.
data = [
'drink cold milk',
'drink cold water',
'drink cold cola',
'drink sweet juice',
'drink sweet cola',
'eat delicious bacon',
'eat sweet mango',
'eat delicious cherry',
'eat sweet apple',
'juice with sugar',
'cola with sugar',
'mango is fruit',
'apple is fruit',
'cherry is fruit',
'Berlin is Germany',
'Boston is USA',
'Mercedes from Germany',
'Mercedes is car',
'Ford from USA',
'Ford is a car'
]
2. 전처리
간단히 모델의 성능을 확인하기 때문에 불용어 처리와 같은 추가 전처리 과정은 거치지 않았다.
2-1. 단어 리스트 생성
단어 : 인덱스 값을 가지는 딕셔너리를 생성해 준다.
이 때 0번은 패딩을 위해 별도로 설정해주었다.
word_sequence = [sequence.split() for sequence in data]
word_list = list(set(" ".join(data).split()))
word2index = {key : idx for idx, key in enumerate(word_list, start = 1)}
word2index['<PAD>'] = 0
vocab_size = len(word_list) + 12-2. Dataset 생성
window size 값에 따라 입력 데이터로 생성되는 과거 단어와 미래 단어의 갯수가 변하게 된다.
window size 값은 2로 설정했다.
window_size = 2
batch_size = 102-2-1. CBOW Dataset 생성
CBOW 모델 학습을 위한 데이터셋을 생성한다.
CBOW_pair라는 함수를 정의한다.
이 과정에서 인덱스를 벗어난 값에 대해서는 패딩을 추가해준다.
CBOW 모델의 경우 입력 데이터가 Embedding Layer로 들어가게 되는데 이 과정에서 입력 데이터는 torch.LongTensor 형식으로 반환해 주었다.
def CBOW_pair(window_size, word_sequence) :
x_train, y_train = [], []
for sequence in word_sequence :
for i in range(len(sequence)) :
y_train.append(word2index[sequence[i]])
context = []
for j in range(window_size, 0, -1) :
# 과거 문자 삽입(With padding)
context.append(word2index[sequence[i-j]] if i - j >= 0 else 0)
for j in range(1, window_size + 1) :
# 미래 문자 삽입(With padding)
context.append(word2index[sequence[i+j]] if i + j < len(sequence) else 0)
# 페어 생성
x_train.append(context)
return torch.LongTensor(x_train), torch.LongTensor(y_train)x_train, y_train = CBOW_pair(window_size, word_sequence)이후 DataLoader를 생성한다.
train_dataset = TensorDataset(x_train, y_train)
train_dataloader = DataLoader(train_dataset, batch_size = batch_size, shuffle = True)
3. Modeling

위 그림과 같이 CBOW 모델은 주변 단어들을 기반으로 중심 단어를 예측하는 모델이다.
그렇기 때문에 주변 단어 들은 임베딩 레이어를 통해 각각의 벡터로 표현되며, 이 벡터들은 projection layer에서 합산이 되어 하나의 벡터로 만들어지게 된다.
이처럼 주변 단어들이 총합된 의미를 담은 하나의 벡터를 생성하게 된다.
CBOW 모델은 아래와 같이 정의하였다.
class CBOW(nn.Module) :
def __init__(self, vocab_size, dimension_size) :
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(vocab_size, dimension_size)
self.linear = nn.Linear(dimension_size, vocab_size, bias = False)
self.activation = nn.LogSoftmax(dim=1)
def forward(self, X) :
X = self.embeddings(X)
X = X.sum(dim = 1)
X = self.linear(X)
X = self.activation(X)
return X
4. Training
모델 학습을 위해 CBOW 모델을 선언하고 가중치 업데이트를 위한 optimizer와 loss function을 설정해 주어야 한다.
optimizer는 SGD를 사용하였으며 Learning Rate는 0.01로 설정했다.
loss function은 분류 문제의 손실함수로서 CrossEntropyLoss()를 사용했다.
Parameter Setting
dimension_size = 5
epochs = 1000Training
model = CBOW(vocab_size, dimension_size)
optimizer = optim.SGD(model.parameters(), lr = 0.01)
criterion = nn.CrossEntropyLoss()
for i in range(epochs + 1) :
for feature, label in train_dataloader :
out = model(feature)
loss = criterion(out, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0 : print("epoch : {:d}, loss : {:0.3f}".format(i, loss))
5. Test
Test를 위해 인덱스 : 단어 로 구성된 딕셔너리를 생성하였다.
index2word = {value : key for key, value in word2index.items()}간단한 더미 데이터를 활용하기 때문에 모델의 정확도를 수치로 계산하는 것보다는 단어 간 유사도를 확인하는 것이 더 적합하다고 판단했다.
5-1. 단어의 유사도 측정
해당 과정에서는 각각의 단어에 대한 유사 단어를 쉽게 확인할 수 있도록 함수를 정의했다.
5-2-1. 유사 단어 상위 3개 추출 함수 생성
def find_similarity(target_word) :
target_word_embed = model.state_dict()['embeddings.weight'][word2index[target_word]]
similarity = []
for i in range(len(word2index)):
if target_word != index2word[i]:
similarity.append(( i, F.cosine_similarity(target_word_embed.unsqueeze(0), model.state_dict()['embeddings.weight'][i].unsqueeze(0)).item()))
else:
similarity.append((i, -1)) # target_word와 동일 단어는 -1 처리
# 유사도 내림차순 정렬
similarity.sort(key = lambda x : -x[1])
# 인덱스를 단어로 변환
print(f'{target_word}와 유사한 단어:')
for i in range(3) :
print(f'{i+1}위 : {index2word[similarity[i][0]]}({similarity[i][1]})')5-2-2. 결과 확인
find_similarity("cola")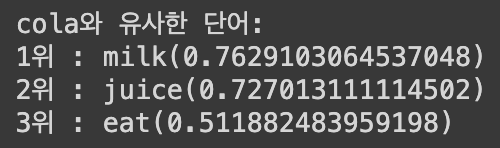
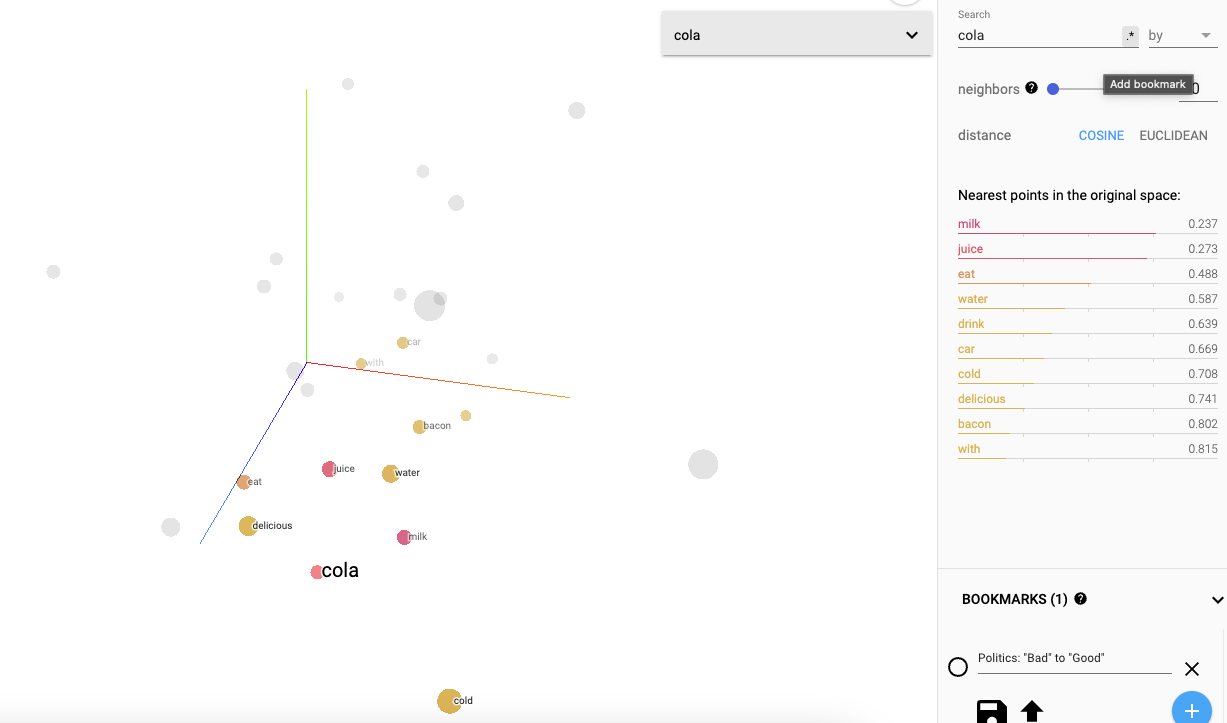
6. 시각화
구글의 임베딩 프로젝터를 활용해 학습한 임베딩 벡터를 시각화했다.
PCA를 생성하여 "cola" 단어를 기준으로 코사인 유사도가 높은 단어를 확인한다.
코사인 유사도가 가장 높은 10개의 단어를 추출한 결과 5-2-2.의 결과와 같이 "milk", "juice", "eat" 순으로 정렬된 것을 확인할 수 있다.