
컴퓨터는 텍스트보다 숫자를 더 잘 처리할 수 있다. 이를 위해 자연어 처리에서는 텍스트를 숫자로 바꾸는 여러 가지 기법들이 있다. 그리고 그러한 기법들을 본격적으로 적용시키기 위한 첫 단계로 각 단어를 고유한 정수에 맵핑시키는 전처리 작업이 필요할 때가 있다.
정수 인코딩
단어에 정수를 부여하는 방법 중 하나로 단어를 빈도수 순으로 정렬한 단어 집합을 만들고, 빈도수가 높은 순서대로 차례로 낮은 숫자로 정수를 부여하는 방법이다. 이에 정수 인코딩으로 변환하는 방식에는 여러 가지가 있다.
raw_text = "A barber is a person. a barber is good person. a barber is huge person. he Knew A Secret! The Secret He Kept is huge secret. Huge secret. His barber kept his word. a barber kept his word. His barber kept his secret. But keeping and keeping such a huge secret to himself was driving the barber crazy. the barber went up a huge mountain."
Dictionary 사용

1. 문장 토큰화
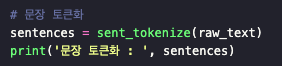
문장 토큰화 : ['A barber is a person.', 'a barber is good person.', 'a barber is huge person.', 'he Knew A Secret!', 'The Secret He Kept is huge secret.', 'Huge secret.', 'His barber kept his word.', 'a barber kept his word.', 'His barber kept his secret.', 'But keeping and keeping such a huge secret to himself was driving the barber crazy.', 'the barber went up a huge mountain.']
2. 전처리

전처리된 문장 리스트 : [['barber', 'person'], ['barber', 'good', 'person'], ['barber', 'huge', 'person'], ['knew', 'secret'], ['secret', 'kept', 'huge', 'secret'], ['huge', 'secret'], ['barber', 'kept', 'word'], ['barber', 'kept', 'word'], ['barber', 'kept', 'secret'], ['keeping', 'keeping', 'huge', 'secret', 'driving', 'barber', 'crazy'], ['barber', 'went', 'huge', 'mountain']]
3. 기록된 빈도 수

단어 집합 : {'barber': 8, 'person': 3, 'good': 1, 'huge': 5, 'knew': 1, 'secret': 6, 'kept': 4, 'word': 2, 'keeping': 2, 'driving': 1, 'crazy': 1, 'went': 1, 'mountain': 1}
4. 빈도 수가 높은 순서대로 정렬

출력 결과 : [('barber', 8), ('secret', 6), ('huge', 5), ('kept', 4), ('person', 3), ('word', 2), ('keeping', 2), ('good', 1), ('knew', 1), ('driving', 1), ('crazy', 1), ('went', 1), ('mountain', 1)]
5. 높은 빈도 수 순서대로 인덱스 부여
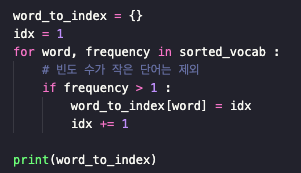
출력 결과 : {'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5, 'word': 6, 'keeping': 7}
6. 상위 5개의 단어 + 단어 집합에 없는 단어 추가
단어 집합에 존재하지 않는 단어들이 생기는 상황을 Out-Of-Vocabulary 문제라고 한다. 약자로 'OOV 문제'라고도 한다.

출력 결과 : {'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5, 'OOV': 6}
7. 인코딩

출력 결과 : [[1, 5], [1, 6, 5], [1, 3, 5], [6, 2], [2, 4, 3, 2], [3, 2], [1, 4, 6], [1, 4, 6], [1, 4, 2], [6, 6, 3, 2, 6, 1, 6], [1, 6, 3, 6]]
Counter 사용하기
1. 주어진 문장의 토큰 합친 후 카운팅

출력 결과 : Counter({'barber': 8, 'secret': 6, 'huge': 5, 'kept': 4, 'person': 3, 'word': 2, 'keeping': 2, 'good': 1, 'knew': 1, 'driving': 1, 'crazy': 1, 'went': 1, 'mountain': 1})
2. 빈도 수가 높은 순서대로 5개 추출

출력 결과 : [('barber', 8), ('secret', 6), ('huge', 5), ('kept', 4), ('person', 3)]
3. 높은 빈도 수 순서대로 인덱스 부여 + 단어 집합에 없는 단어 추가

출력 결과 : {'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5, 'OOV': 6}
NLTK의 FreqDist 사용하기
NLTK에서는 빈도수 계산 도구인 FreqDist()를 지원한다. 위에서 사용한 Counter()와 같은 방법으로 사용할 수 있다.
1. 주어진 문장의 토큰 합친 후 빈도 수가 높은 순서대로 5개 추출

출력 결과 : [('barber', 8), ('secret', 6), ('huge', 5), ('kept', 4), ('person', 3)]
2. 높은 빈도 수 순서대로 인덱스 부여 + 단어 집합에 없는 단어 추가

출력 결과 : {'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5, 'OOV': 6}
Keras의 텍스트 전처리
Keras는 기본적인 전처리를 위한 도구들을 제공한다. 이러한 도구를 활용해 정수 인코딩을 수행할 수 있다.
기본 과정
1. 전처리
전처리 과정은 기존의 과정과 같다.
전처리된 문장 리스트 : [['barber', 'person'], ['barber', 'good', 'person'], ['barber', 'huge', 'person'], ['knew', 'secret'], ['secret', 'kept', 'huge', 'secret'], ['huge', 'secret'], ['barber', 'kept', 'word'], ['barber', 'kept', 'word'], ['barber', 'kept', 'secret'], ['keeping', 'keeping', 'huge', 'secret', 'driving', 'barber', 'crazy'], ['barber', 'went', 'huge', 'mountain']]
2. 빈도수를 기준으로 단어 집합 생성
fit_on_texts는 입력한 텍스트로부터 단어 빈도수가 높은 순으로 낮은 정수 인덱스를 부여하는데, 정확히 앞서 정수 인코딩 작업이 이루어진다고 보면 된다. 각 단어에 인덱스가 어떻게 부여되었는지를 보려면, word_index를 사용하면 된다.

출력 결과 : {'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5, 'word': 6, 'keeping': 7, 'good': 8, 'knew': 9, 'driving': 10, 'crazy': 11, 'went': 12, 'mountain': 13}
위 결과를 통해 각 단어의 빈도수가 높은 순서대로 인덱스가 부여된 것을 확인할 수 있다. 각 단어가 카운트를 수행했을 때 몇 개였는지를 보고자 한다면 word_counts를 사용하면 된다.

출력 결과 : OrderedDict([('barber', 8), ('person', 3), ('good', 1), ('huge', 5), ('knew', 1), ('secret', 6), ('kept', 4), ('word', 2), ('keeping', 2), ('driving', 1), ('crazy', 1), ('went', 1), ('mountain', 1)])
3. 인코딩
text_to_sequences()는 입력으로 들어온 코퍼스에 대해서 각 단어를 이미 정해진 인덱스로 변환한다.

출력 결과 : [[1, 5], [1, 8, 5], [1, 3, 5], [9, 2], [2, 4, 3, 2], [3, 2], [1, 4, 6], [1, 4, 6], [1, 4, 2], [7, 7, 3, 2, 10, 1, 11], [1, 12, 3, 13]]
여러 조건을 충족시키는 과정
Case1. 5개의 빈도수를 가진 전처리 과정
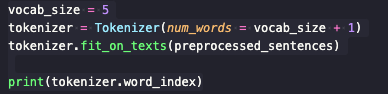
출력 결과 : {'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5, 'word': 6, 'keeping': 7, 'good': 8, 'knew': 9, 'driving': 10, 'crazy': 11, 'went': 12, 'mountain': 13}
상위 5개의 단어만 사용한다고 선언했는데 여전히 13개의 단어가 출력된다. 이것의 실제 적용은 text_to_sequences()를 사용할 때 적용된다.

출력 결과 : [[1, 5], [1, 5], [1, 3, 5], [2], [2, 4, 3, 2], [3, 2], [1, 4], [1, 4], [1, 4, 2], [3, 2, 1], [1, 3]]
Case2. 5개의 빈도수 + 단어 집합에 없는 단어 추가
Keras Tokenizer는 기본적으로 단어 집합에 없는 단어인 OOV에 대해서는 단어를 정수로 바꾸는 과정에서 아예 단어를 제거한다는 특징이 있다. 만약 단어 집합에 없는 단어들은 OOV로 간주하여 보존하고 싶다면 Tokenizer의 인자 oov_token을 사용한다.

출력 결과 : {'OOV': 1, 'barber': 2, 'secret': 3, 'huge': 4, 'kept': 5, 'person': 6, 'word': 7, 'keeping': 8, 'good': 9, 'knew': 10, 'driving': 11, 'crazy': 12, 'went': 13, 'mountain': 14}
출력 결과 : [[2, 6], [2, 1, 6], [2, 4, 6], [1, 3], [3, 5, 4, 3], [4, 3], [2, 5, 1], [2, 5, 1], [2, 5, 3], [1, 1, 4, 3, 1, 2, 1], [2, 1, 4, 1]]
빈도 수 상위 5개의 단어는 2~6까지의 인덱스를 가졌으며, 그 외 단어 집합에 없는 'good'과 같은 단어들은 전부 'OOV'의 인덱스인 1로 인코딩된 것을 확인할 수 있다.
'NLP > 딥러닝을 이용한 자연어 처리 입문' 카테고리의 다른 글
| [NLP] 1-7. 원-핫 인코딩(One-Hot Encoding) (0) | 2023.12.01 |
|---|---|
| [NLP] 1-6. 패딩(Padding) (0) | 2023.12.01 |
| [NLP] 1-4. 불용어(Stopword) (1) | 2023.11.30 |
| [NLP] 1-3. 추출(Stemming) (1) | 2023.11.29 |
| [NLP] 1-2. 정제(Cleaning)와 정규화(Normalization) (0) | 2023.11.29 |