
자연어 처리 과정에서 각 문장의 길이는 서로 다를 수 있다. 하지만 기계는 길이가 전부 동일한 문서들에 대해서는 하나의 행렬로 보고, 한꺼번에 묶어서 처리할 수 있다. 쉽게 말해 병렬 연산을 위해서 여러 문장의 길이를 임의로 동일하게 맞춰주는 작업이 필요할 때가 있다. 이러한 작업은 Numpy로 패딩하는 방법과 Keras 전처리 도구로 패딩하는 방법이 있다.
Numpy로 패딩하기
전처리된 데이터 생성
정수 인코딩 챕터에서 Keras를 활용해 수행했던 결과를 가져온다.
1. 전처리


문장 토큰화 : ['A barber is a person.', 'a barber is good person.', 'a barber is huge person.', 'he Knew A Secret!', 'The Secret He Kept is huge secret.', 'Huge secret.', 'His barber kept his word.', 'a barber kept his word.', 'His barber kept his secret.', 'But keeping and keeping such a huge secret to himself was driving the barber crazy.', 'the barber went up a huge mountain.']
전처리된 문장 리스트 : [['barber', 'person'], ['barber', 'good', 'person'], ['barber', 'huge', 'person'], ['knew', 'secret'], ['secret', 'kept', 'huge', 'secret'], ['huge', 'secret'], ['barber', 'kept', 'word'], ['barber', 'kept', 'word'], ['barber', 'kept', 'secret'], ['keeping', 'keeping', 'huge', 'secret', 'driving', 'barber', 'crazy'], ['barber', 'went', 'huge', 'mountain']]
2. 빈도수를 기준으로 단어 집합 생성

출력 결과 : [[1, 5], [1, 8, 5], [1, 3, 5], [9, 2], [2, 4, 3, 2], [3, 2], [1, 4, 6], [1, 4, 6], [1, 4, 2], [7, 7, 3, 2, 10, 1, 11], [1, 12, 3, 13]]
패딩하기
1. 가장 긴 문장의 길이 체크

출력 결과 : 7
2. 패딩
가장 길이가 긴 문장의 길이는 7이므로, 모든 문장의 길이를 7로 맞춰준다. 이 때 가상의 단어 'PAD'를 사용한다. 'PAD'라는 단어가 있다고 가정하고, 이 단어는 0번 단어라고 정의한다. 길이가 7보다 짧은 문장에는 숫자 0을 채워 길이 7로 맞춰준다.

출력 결과 :
array([[ 1, 5, 0, 0, 0, 0, 0],
[ 1, 8, 5, 0, 0, 0, 0],
[ 1, 3, 5, 0, 0, 0, 0],
[ 9, 2, 0, 0, 0, 0, 0],
[ 2, 4, 3, 2, 0, 0, 0],
[ 3, 2, 0, 0, 0, 0, 0],
[ 1, 4, 6, 0, 0, 0, 0],
[ 1, 4, 6, 0, 0, 0, 0],
[ 1, 4, 2, 0, 0, 0, 0],
[ 7, 7, 3, 2, 10, 1, 11],
[ 1, 12, 3, 13, 0, 0, 0]])
길이가 7보다 짧은 문장에는 전부 숫자 0이 뒤로 붙어서 모든 문장의 길이가 전부 7이 된 것을 알 수 있다. 기계는 이것들을 하나의 행렬로 보고, 병렬 처리를 할 수 있다. 또한, 0번 단어는 사실 아무런 의미도 없는 단어이기 때문에 자연어를 처리하는 과정에서 기계는 0번 단어를 무시하게 될 것이다. 이와 같이 데이터에 특정 값을 채워서 데이터의 크기(shape)를 조정하는 것을 패딩(padding)이라고 한다. 숫자 0을 사용하고 있다면 제로 패딩(zero padding)이라고 한다.
Keras 전처리 도구로 패딩하기
기본 패딩 - 앞을 0으로 채우기
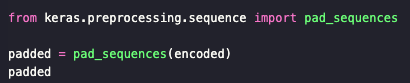
출력 결과 :
array([[ 0, 0, 0, 0, 0, 1, 5],
[ 0, 0, 0, 0, 1, 8, 5],
[ 0, 0, 0, 0, 1, 3, 5],
[ 0, 0, 0, 0, 0, 9, 2],
[ 0, 0, 0, 2, 4, 3, 2],
[ 0, 0, 0, 0, 0, 3, 2],
[ 0, 0, 0, 0, 1, 4, 6],
[ 0, 0, 0, 0, 1, 4, 6],
[ 0, 0, 0, 0, 1, 4, 2],
[ 7, 7, 3, 2, 10, 1, 11],
[ 0, 0, 0, 1, 12, 3, 13]], dtype=int32)
Numpy로 패딩했을 때와는 결과가 다른데, 그 이유는 pad_sequence는 기본적으로 문서의 앞을 0으로 채우기 때문이다. 만약 뒤를 0으로 채우고 싶다면 인자로 padding = 'post'를 주면 된다.
뒤를 0으로 채우기

출력 결과 :
array([[ 1, 5, 0, 0, 0, 0, 0],
[ 1, 8, 5, 0, 0, 0, 0],
[ 1, 3, 5, 0, 0, 0, 0],
[ 9, 2, 0, 0, 0, 0, 0],
[ 2, 4, 3, 2, 0, 0, 0],
[ 3, 2, 0, 0, 0, 0, 0],
[ 1, 4, 6, 0, 0, 0, 0],
[ 1, 4, 6, 0, 0, 0, 0],
[ 1, 4, 2, 0, 0, 0, 0],
[ 7, 7, 3, 2, 10, 1, 11],
[ 1, 12, 3, 13, 0, 0, 0]], dtype=int32)
길이 조정하기
지금까지는 가장 긴 길이를 가진 문서의 길이를 기준으로 패딩을 했지만, 실제로는 꼭 가장 긴 문서의 길이를 기준으로 해야 하는 것은 아니다. 가령, 모든 문서의 평균 길이가 20인데 문서 1개의 길이가 5,000이라고 해서 굳이 5000으로 패딩할 필요는 없다. 이와 같은 경우에는 길이에 제한을 두고 패딩할 수 있다. maxlen의 인자로 정수를 주면, 해당 정수로 모든 문서의 길이를 동일하게 한다.

출력 결과 :
array([[ 1, 5, 0, 0, 0],
[ 1, 8, 5, 0, 0],
[ 1, 3, 5, 0, 0],
[ 9, 2, 0, 0, 0],
[ 2, 4, 3, 2, 0],
[ 3, 2, 0, 0, 0],
[ 1, 4, 6, 0, 0],
[ 1, 4, 6, 0, 0],
[ 1, 4, 2, 0, 0],
[ 3, 2, 10, 1, 11],
[ 1, 12, 3, 13, 0]], dtype=int32)
뒤의 문자 삭제하기
길이가 5보다 짧은 문서들은 0으로 패딩되고, 기존에 5보다 길었다면 데이터가 손실된다. 가령, 뒤에서 두 번째 문장은 본래 [ 7, 7, 3, 2, 10, 1, 11]였으나 현재는 [ 3, 2, 10, 1, 11]로 변경된 것을 볼 수 있다.만약,데이터가 손실될 경우에 앞의 단어가 아니라 뒤의 단어가 삭제되도록 하고 싶다면 truncating이라는 인자를 사용하면 된다. truncating = 'post'를 사용할 경우 뒤의 단어가 삭제된다.

출력 결과 :
array([[ 1, 5, 0, 0, 0],
[ 1, 8, 5, 0, 0],
[ 1, 3, 5, 0, 0],
[ 9, 2, 0, 0, 0],
[ 2, 4, 3, 2, 0],
[ 3, 2, 0, 0, 0],
[ 1, 4, 6, 0, 0],
[ 1, 4, 6, 0, 0],
[ 1, 4, 2, 0, 0],
[ 7, 7, 3, 2, 10],
[ 1, 12, 3, 13, 0]], dtype=int32)
다른 숫자로 패딩하기
숫자 0으로 패딩하는 것은 널리 퍼진 관례이긴 하지만, 반드시 지켜야 하는 규칙은 아니다. 만약, 숫자 0이 아니라 다른 숫자를 패딩을 위한 숫자로 사용하고 싶다면 가능하다. 이 때는 pad_sequences의 인자로 value를 사용하면 0이 아닌 다른 숫자로 패딩이 가능하다.

출력 결과 :
array([[ 1, 5, 14, 14, 14, 14, 14],
[ 1, 8, 5, 14, 14, 14, 14],
[ 1, 3, 5, 14, 14, 14, 14],
[ 9, 2, 14, 14, 14, 14, 14],
[ 2, 4, 3, 2, 14, 14, 14],
[ 3, 2, 14, 14, 14, 14, 14],
[ 1, 4, 6, 14, 14, 14, 14],
[ 1, 4, 6, 14, 14, 14, 14],
[ 1, 4, 2, 14, 14, 14, 14],
[ 7, 7, 3, 2, 10, 1, 11],
[ 1, 12, 3, 13, 14, 14, 14]], dtype=int32)
'NLP > 딥러닝을 이용한 자연어 처리 입문' 카테고리의 다른 글
| [NLP] 2. 언어 모델(Language Model) (0) | 2023.12.04 |
|---|---|
| [NLP] 1-7. 원-핫 인코딩(One-Hot Encoding) (0) | 2023.12.01 |
| [NLP] 1-5. 정수 인코딩 (0) | 2023.11.30 |
| [NLP] 1-4. 불용어(Stopword) (1) | 2023.11.30 |
| [NLP] 1-3. 추출(Stemming) (1) | 2023.11.29 |